
- Logged on as
- Dashboard
- Change password
- Log out
“Hello, World” Tutorial (Ruby)
This Tutorial is for webmaster/programmers. By practicing simple tasks at the command line, you will learn the basics of how to:
- Sign up for Searchify
- Create an index and populate it with searchable text
- Send search queries to the index and understand the results
- Tweak the search results and influence the order in which they appear (with scoring functions and variables)
- Delete documents
Before You Start
To run the tutorial, you will need:
- Ruby (1.8.7), RubyGems (1.3.7+), irb (0.9.5+) installed on your machine (Searchify can be used with other languages, but in this Tutorial we use Ruby. If you don't already have Ruby, you can get it at ruby-lang.org).
- Internet access (You must be able to view www.searchify.com in a Web browser) .
- Knowledge of your computer's command prompt (You will need to open a console window and issue commands at the prompt in order to perform the steps in the tutorial) .
System requirements:
- The Tutorial has been tested on Linux..
The following would be helpful before you start, but are not required:
- Working knowledge of a programming language (You will be able to complete the Tutorial just by following along with our example code, but in order to build a real application using what you've learned, you will have to do some real programming through our HTTP API or, more likely, one of our client libraries) .
- Read the FAQ to familiarize yourself with the vocabulary and general architecture of Searchify (The Tutorial will go more smoothly if you already know what kinds of things you can do with Searchify, what an index is, and so on. Each step in the tutorial will provide links to any relevant FAQ sections, so, if you prefer, you can learn each concept at the moment you need to know it rather than reading all the concepts ahead of time) .
About The Example App
The Tutorial shows the process for setting up an index and performing some example queries on a fictitious web site that includes a forum where members discuss video games.
Step 1: Sign Up for Searchify's Free Plan
-
Open your browser and go to http://www.searchify.com/plans and choose one of the plans.
-
Enter your email address and a desired password.
Result:
The Searchify dashboard appears, showing your new account:
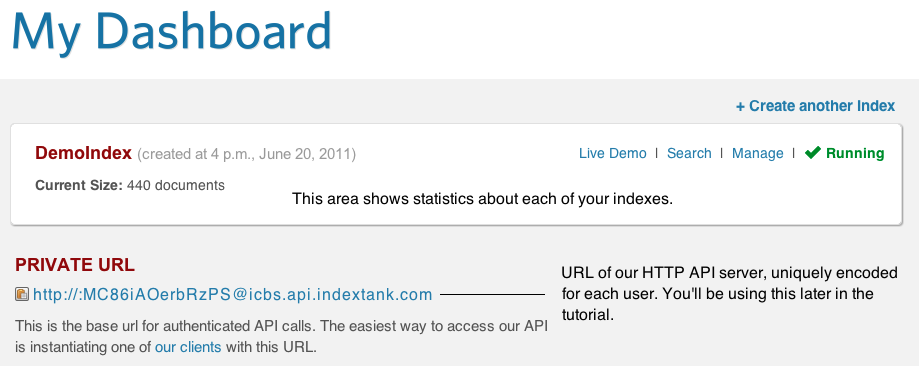
Step 2: Create an Empty Index
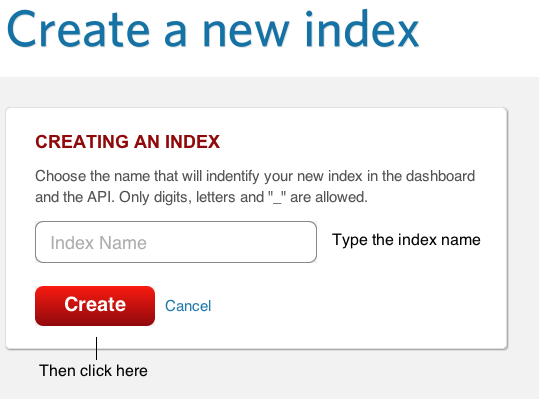
-
Click new index.

-
In Index Name, type test_index.
-
Click Create Index.
Result:
The dashboard is displayed. In INDEX NAME, test_index appears. In STATUS, you can see whether the index is ready to use:
-
Wait for a short time (typically less than one minute) to give Searchify time to set up the cloud resources for your index.
-
Click your browser's Refresh button.
If STATUS has changed to Running, you can proceed to the next part of the tutorial. If STATUS is still Initializing, wait a bit, then hit Refresh again.

Result:
You now have an empty index that is ready to be populated with content.
Step 3: Download the Client Library
-
Click client documentation or go to http://www.searchify.com/documentation.

-
Click Ruby client library. This takes you to
http://www.searchify.com/documentation/ruby-client. -
Follow the instructions in the client library documentation to install the client gem (may require admin privileges).
$ gem install 'indextank'
Step 4: Instantiate the Client
-
Run the Ruby interpreter (irb).
$ irb
The Ruby prompt appears:
irb(main):001:0>
Import the IndexTank client library to the Ruby interpreter by typing the following command at the irb prompt.
irb(main):001:0> require 'rubygems' irb(main):002:0> require 'indextank'
-
Instantiate the client.
irb(main):003:0> api_client = IndexTank::Client.new 'YOUR_API_URL'
For
YOUR_API_URL, substitute the URL from Private URL in your Dashboard (refer to the screen shot at the beginning of the Tutorial if you forgot where to find this).
Step 5: Set Up the Index
-
Get a handle to your test index.
irb(main):004:0> test_index = api_client.indexes 'test_index'
Here we call the
indexesmethod in the client library and pass it the name you assigned when you created the index. -
Add some documents to the index.
irb(main):005:0> test_index.document('post1').add({ :text => 'I love Bioshock' }) irb(main):006:0> test_index.document('post2').add({ :text => 'Need cheats for Bioshock' }) irb(main):007:0> test_index.document('post3').add({ :text => 'I love Tetris' })Here we call the
document().add()method in the client library three times to index three posts in the video gamer forum.NOTE: In a real application, the doc ID would most likely be a URL.post1,post2, andpost3are unique alphanumeric IDs you give to the documents. If the doc ID is not unique, you will overwrite the existing document with the same ID, so watch out for typos during this Tutorial!The method parameters are name:value pairs that build up the index for one document. In this example, there is a single name:value pair for each forum post.
textis a field name, and it has a special meaning to Searchify: in search queries, Searchify defaults to searchingtextif the query does not specify a different field. You'll learn more about this later, in Use Fields to Divide Document Text.
Result:
test_index now contains:
| Doc ID | Field | Value |
|---|---|---|
| post1 | text | I love Bioshock |
| post2 | text | Need cheats for Bioshock |
| post3 | text | I love Tetris |
Step 6: Search Documents Using the Index
-
Suppose you're interested in a particular game, and you want to find all the posts that contain Bioshock:
irb(main):008:0> test_index.search 'Bioshock'
The output should look like this (you can ignore
facetsfor now). The search term was found in post1 and post2:{'matches' => 2, 'facets' => {}, 'search_time' => '0.070', 'results' => [{'docid' => 'post2'},{'docid' => 'post1'}]}NOTE: AND is the default search operator, so you can just list all the search terms. -
Suppose you want to find only the true enthusiasts on the forum. You can search for posts that contain Bioshock and love.
irb(main):009:0> test_index.search 'love Bioshock'
The output should look like this. The two search terms were found together only in post1:
{'matches' => 1, 'facets' => {}, 'search_time' => '0.005', 'results' => [{'docid' => 'post1'}]} -
You can also use the query operators OR and NOT. Let's try OR, which would come in handy if you play more than one game and you want to find posts that mention any of your favorites.
irb(main):010:0> test_index.search 'Bioshock OR Tetris'
The output should look like this:
{'matches' => 3, 'facets' => {}, 'search_time' => '0.007', 'results' => [{'docid' => 'post3'},{'docid' => 'post2'},{'docid' => 'post1'}]} -
To ask Searchify to return more than just the doc ID, add the argument
:fetch => 'field'.irb(main):011:0> test_index.search('love', :fetch => 'text' )['results']Here,
textmeans we would like the full text of the document where the search term was found. This would be useful, for example, to construct an output page that provides complete result text for the reader to look at. The output should look like this:[{'text' => 'I love Tetris', 'docid' => 'post3'}, {'text' => 'I love Bioshock', 'docid' => 'post1'}] -
To show portions of the result text with the search term highlighted, use
:snippet => 'field'.irb(main):012:0> test_index.search('love', :snippet => 'text')['results']The output should look like this:
[{'snippet_text' => 'I <b>love</b> Tetris', 'docid' => 'post3'}, {'snippet_text' => 'I <b>love</b> Bioshock', 'docid' => 'post1'}]
text,
so the search query doesn't have to specify a field.
Step 7: Use Fields to Divide Document Text
So far, we have worked with simple document index entries that contain only a single field,
text,
containing the complete text of the document. Let's redefine the documents now and add some more fields to enable more targeted searching.
-
Set up two fields for each document: the original
textfield plus a new field,game, that contains the name of the video game that is the subject of the forum post.irb(main):013:0> test_index.document('post1').add({ :text => 'I love Bioshock', :game => 'Bioshock' }) irb(main):014:0> test_index.document('post2').add({ :text => 'Need cheats for Bioshock', :game => 'Bioshock' }) irb(main):015:0> test_index.document('post3').add({ :text => 'I love Tetris', :game => 'Tetris' })Here we call
document().add()with the same document IDs as before, so Searchify will overwrite the existing entries in your test index.Result:
test_index now contains:Doc ID Field Value post1 text I love Bioshock game Bioshock post2 text Need cheats for Bioshock game Bioshock post3 text I love Tetris game Tetris -
Now you can search within a particular field. Let's use
fetchagain to get some user-friendly output.irb(main):016:0> test_index.search('game:Tetris', :fetch => 'text')['results']Note that we can return the contents of a field even if it is not being searched. The output should look like this:
[{'text' => 'I love Tetris', 'docid' => 'post3'}]
Step 8: Customize Result Ranking with Scoring Functions
A scoring function
is a mathematical formula that you can reference in a query to influence the ranking of search results. Scoring functions are named with integers starting at 0 and going up to 5. Function 0 is the default and will be applied if no other is specified; it starts out with an initial definition of
-age,
which sorts query results from most recently indexed to least recently indexed (newest to oldest).
Function 0 uses the
timestamp
field which Searchify provides for each document. The time is recorded as the number of seconds since epoch. Searchify automatically sets each document's timestamp to the current time when the document is indexed, but you can override this timestamp. To make this scoring function tutorial easier to follow, that's what we are going to do.
-
Assign timestamps to some new posts in the index.
irb(main):017:0> test_index.document('newest' ).add({ :text => 'New release: Fable III is out', :timestamp => 1286673129 }) irb(main):018:0> test_index.document('not_so_new').add({ :text => 'New release: GTA III just arrived!', :timestamp => 1003626729 }) irb(main):019:0> test_index.document('oldest' ).add({ :text => 'New release: This new game Tetris is awesome!', :timestamp => 455332329 }) -
Search using the default scoring function.
irb(main):020:0> test_index.search 'New release'
The output should look like this. The default scoring function has sorted the documents from newest to oldest:
{'matches' => 3, 'facets' => {}, 'search_time' => '0.002', 'results' => [{'docid' => 'newest'},{'docid' => 'not_so_new'},{'docid' => 'oldest'}]} -
Redefine function 0 to sort in the opposite order, by removing the negative sign from the calculation.
irb(main):021:0> test_index.functions(0, 'age').add
-
Search again.
irb(main):022:0> test_index.search 'New release'
The output should look like this. The oldest document is now first:
{'matches' => 3, 'facets' => {}, 'search_time' => '0.005', 'results' => [{'docid' => 'oldest'},{'docid' => 'not_so_new'},{'docid' => 'newest'}]} -
Let's try creating another scoring function, function 1, using a different Searchify built-in score called
relevance. Relevance is calculated using a proprietary algorithm, and indicates which documents best match a query. First, add some test documents that will more clearly illustrate the effect of the relevance score.irb(main):023:0> test_index.document('post4').add({ :text => 'When is Duke Nukem Forever coming out? I need my Duke.'}) irb(main):024:0> test_index.document('post5').add({ :text => 'Duke Nukem is my favorite game. Duke Nukem rules. Duke Nukem is awesome. Here are my favorite Duke Nukem links.'}) irb(main):025:0> test_index.document('post6').add({ :text => 'People who love Duke Nukem also love our great product!'}) -
Now define function 1.
irb(main):026:0> test_index.functions(1,'relevance').add
-
Search using the new scoring function.
irb(main):027:0> test_index.search('duke', :function => 1, :fetch => 'text' )['results']The output should look like this. The most relevant document is now first:
[{'docid' => 'post5', 'text' => 'Duke Nukem is my favorite game. Duke Nukem rules. Duke Nukem is awesome. Here are my favorite Duke Nukem links.'}, {'docid' => 'post4', 'text' => 'When is Duke Nukem Forever coming out? I need my Duke.'}, {'docid' => 'post6', 'text' => 'People who love Duke Nukem also love our great product!'}]
Step 9: Add Document Variables To Your Scoring Functions
In addition to textual information, each document can have up to three (3) document variables to store any numeric data you would like. Each variable is referred to by number, starting with variable 0. Document variables provide additional useful information to create more subtle and effective scoring functions.
For example, assume that in the video game forum, members can vote for posts that they like. The forum application keeps track of the number of votes. These vote totals can be used to push the more popular posts up higher in search results.
Let's also assume that the forum software assigns a spam score by examining each new post for evidence that it is from a legitimate forum member and contains relevant content, and then assigning a confidence value from 0 (almost certainly spam) to 1 (high confidence that the post is legitimate).
-
Assign the total votes to document variable 0 and the spam score to document variable 1.
irb(main):028:0> test_index.document('post4').add({ :text => 'When is Duke Nukem Forever coming out? I need my Duke.'}, :variables => { 0 => 10, 1 => 1.0 }) irb(main):029:0> test_index.document('post5').add({ :text => 'Duke Nukem is my favorite game. Duke Nukem rules. Duke Nukem is awesome. Here are my favorite Duke Nukem links.'}, :variables => { 0 => 1000, 1 => 0.9 }) irb(main):030:0> test_index.document('post6').add({ :text => 'People who love Duke Nukem also love our great product!'}, :variables => { 0 => 1, 1 => 0.05 }) -
Use the document variables in a scoring function.
irb(main):031:0> test_index.functions(2, 'relevance * log(doc.var[0]) * doc.var[1]').add
-
Run a query using the scoring function.
irb(main):032:0> test_index.search('duke', :function => 2, :fetch => 'text' )['results']The output should look like this:
[{'docid' => 'post5', 'text' => 'Duke Nukem is my favorite game. Duke Nukem rules. Duke Nukem is awesome. Here are my favorite Duke Nukem links.'}, {'docid' => 'post4', 'text' => 'When is Duke Nukem Forever coming out? I need my Duke.'}, {'docid' => 'post6', 'text' => 'People who love Duke Nukem also love our great product!'}] -
When more readers vote for a post, update the vote total in variable 0.
irb(main):033:0> test_index.document('post4').update_variables({ 0 => 1000000 }) -
Now run the query again with the same scoring function.
irb(main):034:0> test_index.search('duke', :function => 2, :fetch => 'text' )['results']The output should show the new most-popular post first:
[{'docid' => 'post4', 'text' => 'When is Duke Nukem Forever coming out? I need my Duke.'}, {'docid' => 'post5', 'text' => 'Duke Nukem is my favorite game. Duke Nukem rules. Duke Nukem is awesome. Here are my favorite Duke Nukem links.'}, {'docid' => 'post6', 'text' => 'People who love Duke Nukem also love our great product!'}]
Step 10: Delete a Document
If you're 100% confident something should not be in the index, it makes sense to remove it.
-
Take out that spam document.
irb(main):035:0> test_index.document('post6').delete -
Search again to confirm the deletion.
irb(main):036:0> test_index.search('duke', :function => 2, :fetch => 'text' )['results']The output should show only two results:
[{'docid' => 'post5', 'text' => 'Duke Nukem is my favorite game. Duke Nukem rules. Duke Nukem is awesome. Here are my favorite Duke Nukem links.'}, {'docid' => 'post4', 'text' => 'When is Duke Nukem Forever coming out? I need my Duke.'}]
Step 11: Use Variables to Refine Queries
You can pass variables with a query and use them as input to a scoring function. This is useful, for example, to customize results for a particular user. Suppose we're dealing with the search on the forum site. It makes sense to index the poster's gamerscore to use it as part of the matching process.
-
Add a document variable. This will be compared to the query variable later. Here variable 0 holds the gamerscore of the person who made the post:
irb(main):037:0> test_index.document('post1').add({ :text => 'I love Bioshock'}, :variables => { 0 => 115 }) irb(main):038:0> test_index.document('post2').add({ :text => 'Need cheats for Bioshock'}, :variables => { 0 => 2600 }) irb(main):039:0> test_index.document('post3').add({ :text => 'I love Tetris'}, :variables => { 0 => 19500 }) -
Suppose we want to boost posts from forum members with a gamerscore closer to that of the searcher. Let's define a scoring function to do that.
irb(main):040:0> test_index.functions(1, 'relevance / max(1, abs(query.var[0] - doc.var[0]))').add
This scoring function prioritizes gamerscores close to the searcher's own (
query.var[0]). The absolute (abs) function is there to provide symmetry for gamerscores above and below the searcher's. Themaxfunction ensures that we never divide by 0, and evens out all gamerscore differences less than 1 (in case we use floats for the gamerscores, instead of integers). -
Suppose John is the searcher, with a gamerscore of 25. In the query, set variable 0 to the gamerscore.
irb(main):041:0> test_index.search('bioshock', :function => 1, :fetch => 'text', :variables => { 0 => 25 })['results']The output should look like this:
[{'docid' => 'post1', 'text' => 'I love Bioshock.'}, {'docid' => 'post2', 'text' => 'Need cheats for Bioshock.'}] -
For Isabelle, gamerscore 15,000:
irb(main):042:0> test_index.search('love', :function => 1, :fetch => 'text', variables => { 0 => 15000 })['results']The output should look like this:
[{'docid' => 'post3', 'text' => 'I love Tetris.'}, {'docid' => 'post1', 'text' => 'I love Bioshock.'}]
Next Steps
Now that you have learned some of the basic functionality of Searchify, you are ready to go more in-depth:
- Client library documentation will tell you more about the specific capabilities and syntax of the client in your programming language.
- Scoring functions goes into much more detail about formulas, operators, variables, and functions.
Enjoy using Searchify to improve the quality of search on your website.
Table of contents
- Before You Start
- About the Example App
- Step 1: Sign Up for Searchify's Free Plan
- Step 2: Create an Empty Index
- Step 3: Download the Client Library
- Step 4: Instantiate the Client
- Step 5: Set Up the Index
- Step 6: Search Documents Using the Index
- Step 7: Use Fields to Divide Document Text
- Step 8: Customize Ranking with functions
- Step 9: Add Document Variables to functions
- Step 10: Delete a Document
- Step 11: Use Variables to Refine Queries
- Next Steps